Counting the number of points in a polygon is a common overlay operation. But unless you’re aware of what happens when points fall on polygon boundaries, or when points fall just outside the coverage of your polygons, you may not be getting the results you expect.
 Here’s the scenario:
Here’s the scenario:
- I have polygons representing some administrative districts.
- And I have some points representing households. Each household has an attribute HHSize which is the number of people in the household.
- I want to count the number of households and the total size of the household in each polygon.
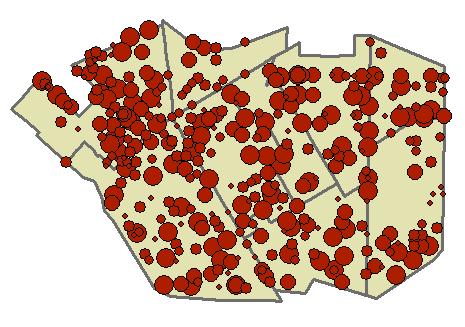
The map to the left shows the household points with graduated symbols based on HHSIZE.
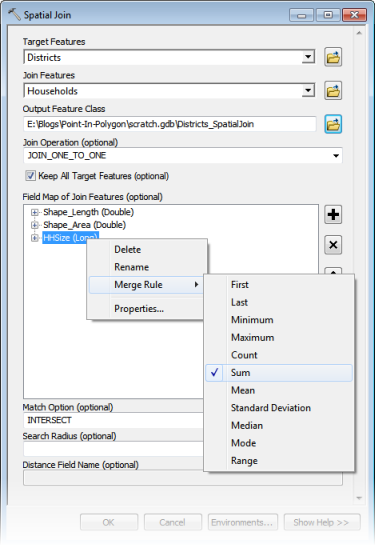 There are lots of ways to perform the overlay to get the number of households and the sum of household size. For now, let’s look at what I would describe as the “standard method”: Spatial Join, shown to the right. The Target Featuresare the polygons (Districts) and the Join Features are the points (Households). Since I want the sum of HHSize, I right-click the HHSize field in the Field Map and choose Sum as the Merge Rule. The Match Option is INTERSECT.
There are lots of ways to perform the overlay to get the number of households and the sum of household size. For now, let’s look at what I would describe as the “standard method”: Spatial Join, shown to the right. The Target Featuresare the polygons (Districts) and the Join Features are the points (Households). Since I want the sum of HHSize, I right-click the HHSize field in the Field Map and choose Sum as the Merge Rule. The Match Option is INTERSECT.
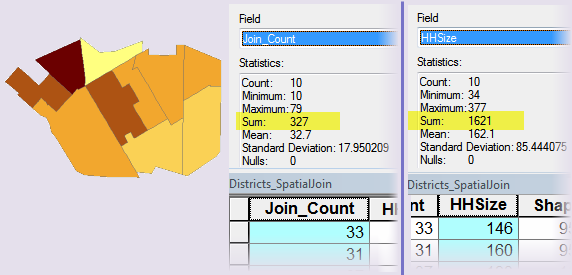
The figure below shows the output of Spatial Join, the Districts_SpatialJoin feature class, symbolized by the sum of HHSize, and its table with statistics about the Join_Count field (the number of points found in the polygon) and the HHSize field (the sum of all HHSize values for the polygon). These statistics tell us that 327 points were overlaid and the sum of HHSize for all polygons is 1621.
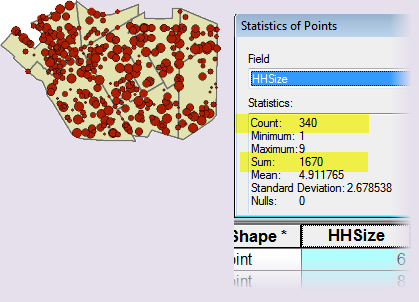
Now let’s go back to the Households table and get some statistics. There are 340 points with a HHSize total of 1670.
Huh? Out of the original 340 points, only 327 were found to intersect the polygons. The HHSize sums are off as well; instead of 1670, there’s 1621. Why the difference?
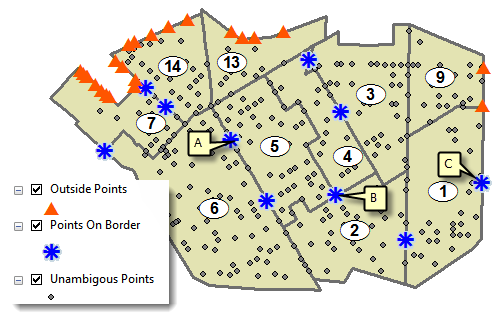
The issue is that some points are ambiguous; some fall outside the coverage of the polygons and some fall exactly on polygon boundaries, as shown on the map to the left. The red triangles show points that fall outside the coverage of the polygons and do not overlay any of the polygons. So they don’t get counted at all. More interesting are the blue asterisks that show points that fall exactly on a polygon boundary. When a point falls exactly on a polygon boundary, it gets overlaid with each polygon that shares the boundary. In the figure, point A overlays two districts and gets counted twice, once in district 5 and once in district 6. Point B overlays districts 2, 4, and 5 and gets counted thrice. Point C, although on a border, gets counted only once since it falls on an exterior boundary.
Finding boundary points
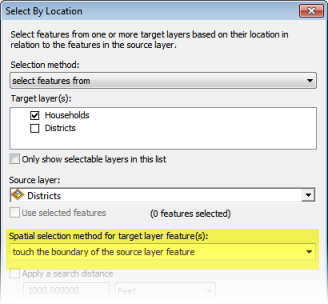
To find boundary points, use the Select By Location tool found in the Selection menu of ArcMap. The Target layer is the point layer (Households) and the Source layer is the polygon layer (Districts). The Spatial selection method is “touch the boundary of the source layer feature“.
The result is a selection of points that fall exactly on the boundary of a polygon.
Finding points outside
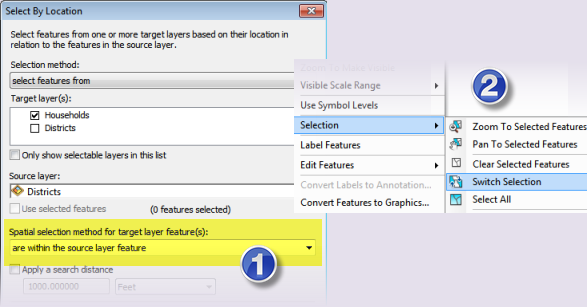
To find points that fall outside the coverage of the polygons, use Select By Location with the same inputs as above (be sure to clear any selections beforehand), but choose “are within the source layer feature” for the Spatial Selection method. This selects all points that are covered by the polygons. Next, right click the point layer (Households), and click Selection > Switch Selection. The result is a selection of points that fall outside the coverage of the polygons.
If you have any ambiguous points (border points or outside points), you need to determine what to do with them before doing any point-in-polygon analysis.
- Are the outside points truly outside? In this example, the outside points are just a few meters away from a polygon boundary, and I want them to overlay the closest polygon. For your data, you’ll have to decide based on your data resolution and quality whether outside points should overlay a polygon.
- For boundary points, do you care which polygon they overlay? For some analyses, you may want the point to overlay each polygon that shares a boundary (because, technically, the point does belong in each polygon). Or you just don’t care — just have the software randomly assign the point to one (and only one) of the shared polygons.
You could, of course, edit the points and move them inside the polygon to which they belong, but this requires you have more information than just the location of the point, which means you may have some attribute about each point that tells you what polygon the point should overlay. And if you have this information, you may not have to do an overlay; you’d use the attribute in something like Summary Statistics to calculate totals for each polygon. If your points are the result of geocoding addresses, see the section at the end of this post; it may be that you need to geocode your addresses again using a side offset.
So, if editing and moving the points isn’t an option (either because there’s too many or there’s no other information), you need something other than the “standard method” of using Spatial Join shown above. My favorite is…
Use proximity, not overlay
In may seem counter-intuitive, but instead of using an overlay function to do point-in-polygon analysis, use a proximity function.
In ArcGIS, the proximity tools (such as Near and Generate Near Table) have a unique (but not unexpected) behavior: when two or more nearby features are equal-distant from the target feature, one of the nearby features is chosen at random. When a point falls on a polygon boundary, it is equidistant from all bounding polygons. That means that one of the bounding polygons is chosen at random to be the closest polygon, and over-counting is eliminated.
Here’s a model that does point-in-polygon analysis using the Near tool.

Below are details about each tool in the model.
Near
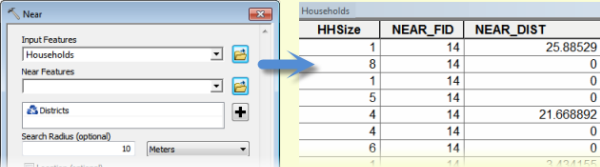
- Input Features is Households (points).
- Near Features is Districts (polygons).
- Search Radius is 10 meters (or whatever is appropriate to capture the outside points). If you only want to deal with boundary points and disregard any outside points, set the Search Radius to 0 (zero).
- The output is Households with NEAR_FID and NEAR_DIST. NEAR_FID is the OBJECTID of the closest polygon and NEAR_DIST is the distance in the units of the input point features. For points inside or on polygon boundaries, NEAR_DIST is zero. For points on boundaries, one of the nearest polygons is selected at random. If no polygon is found, NEAR_FID and NEAR_DIST are -1.
Summary Statistics
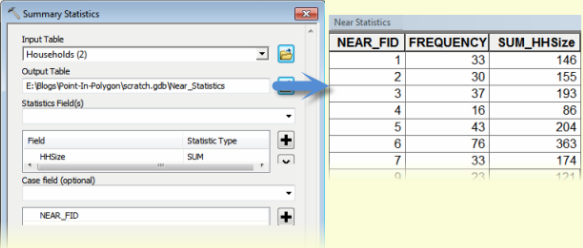
- Input Table is the output of Near.
- Statistics Field is HHSize with a Statistics Type of SUM.
- Case field is NEAR_FID
- The output is a table with one row for each unique value of NEAR_FID. Because NEAR_FID is the OBJECTID of the polygons, the output has one row for each input polygon (unless there’s a polygon that is not near any of the points). The output also contains SUM_HHSize, the sum of all HHSize values for each unique NEAR_FID. The output also contains a FREQUENCY field, which is the number of records for each unique Case field, which is the number of points in each polygon. The statistics are correct as well; the sum of FREQUENCY is the total number of points (340) and SUM_HHSize is correct (1670).
- Hint: If all you need is a count of points, set the Statistics Field to OBJECTID and the Statistics Type to COUNT, and set the Case Fieldto NEAR_FID. The output table will contain COUNT_OBJECTID and FREQUENCY
Join Field
- This step is optional; the output table of Summary Statistics is permanently joined back to the input polygons (Districts). For your project, it may be that that all you need is the output statistics table.
- Input Table is Districts
- Input Join Field is OBJECTID
- Join Table is Near Statistics (the output of Summary Statistics)
- Output Join Field is NEAR_FID
- Join Fields are FREQUENCY and SUM_HHSize
Address Matching
Points that fall on polygon boundaries are usually the result of geocoding addresses to street centerlines that also form polygon boundaries (in the example above, the Districts feature class uses streets centerlines as polygon boundaries). If a side offset is not specified when geocoding addresses, the geocoded points will fall exactly on the street centerlines and, by association, the polygon boundaries. So, to avoid an ambiguous points situation, you’ll want to specify a side offset on the address locator you use for geocoding. An offset of just a few feet or meters is all you need to avoid ambiguity.
Best Practices
To wrap this up, if you’re doing a point-in-polygon analysis, you need to investigate your data before performing the analysis:
- Use the Select By Location tool in ArcMap as shown above to determine if you have any ambiguous points (points outside or on boundaries).
- If you don’t have any ambiguous points, you can use the “standard method” of Spatial Join.
- If you have ambiguous points, you can use the proximity method shown in the above model. If you have outside points that you want to include, use an appropriate non-zero Search Radius in the Near tool. If you only want to include boundary points (no outside points), use a Search Radius of 0 (zero).
- Check your results by examining your input and output data using the statistics tool available when viewing tables in ArcMap.
Commenting is not enabled for this article.