
In today’s data-driven world, organizations are increasingly relying on real-time and big data analytics to make informed decisions. As they collect and analyze growing amounts of real-time and historical data, the importance of data retention becomes evident. In this blog, we will explore the key aspects of data retention in ArcGIS Velocity, including the settings available for data retention, how long to keep data for, and how to ingest data from a feature layer archive.
What is data retention?
This parameter allows you to specify how long you want the data to be actively maintained in the feature layer. For example, if you have a live feed of vehicle positions and you want to store the historical tracks in a feature layer, you can set the data retention policy to maintain a history of vehicle positions for a set time period. Data retention gives you a way to have more control over your data by keeping it relevant and at a manageable size.
Why is data retention necessary on a feature layer?
Consider a transportation company that utilizes a feature layer to track vehicle locations in real-time. Over months of operation, this layer may accumulate hundreds of thousands of records, including historical locations for each vehicle. The feature layer may experience performance reductions as data accumulates, such as slower response time and decreased query speed. To address this, Velocity offers flexible storage solutions, with layers supporting up to one year of storage within your specified limits. This accumulation of data not only complicates data handling but makes it challenging to visualize insights.
Implementing data retention can directly address this challenge by allowing users to define a period of time to retain data in a feature layer. By removal of older, less relevant data, organizations can ensure that their feature layers remain streamlined and focused, thus enhancing performance while still retaining essential historical information for analysis.
What is data retention not intended for?
Data retention is not intended to limit or filter features to specific time frames. For example, you want a feature layer to show the vehicle positions from the last hour for the most current view of your fleet. Even if you set the data retention period to one hour, vehicle position records may still be retained for two to three hours because the data removal process operates on a periodic schedule. If you need filter data from specific time periods, you must use alternative methods, such as queries in client applications.
How do I configure data retention in a feature layer?
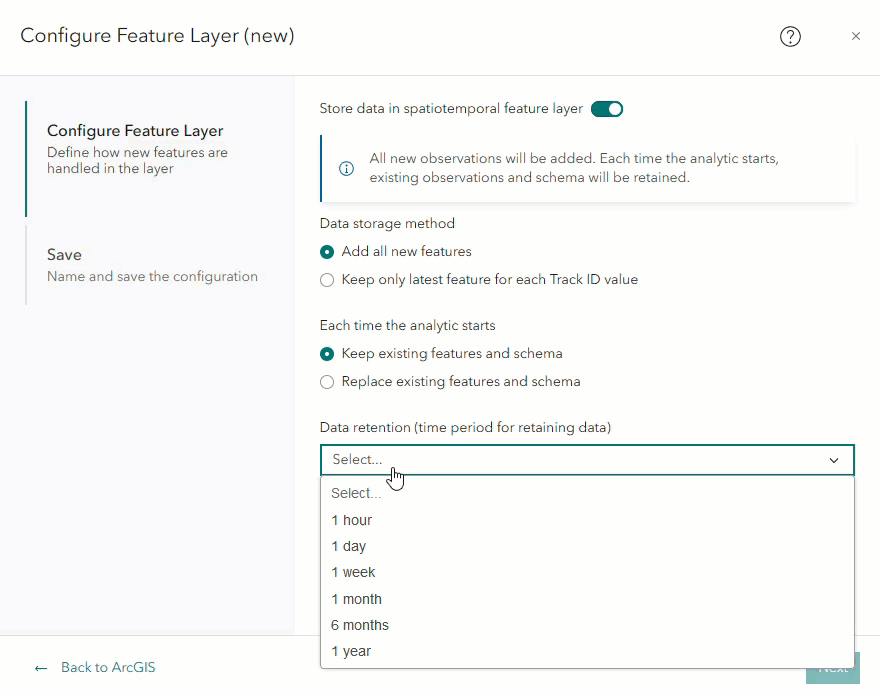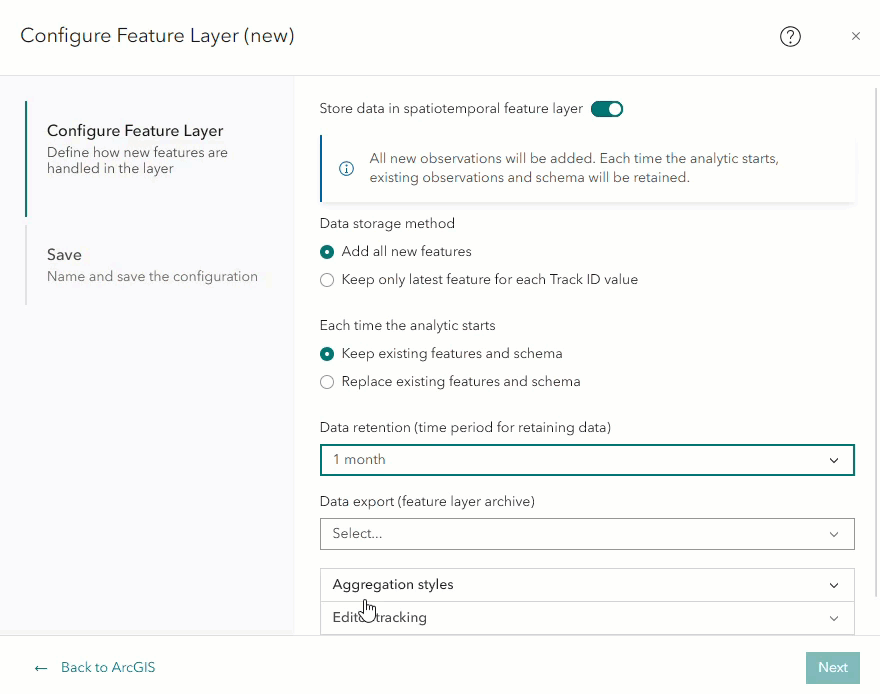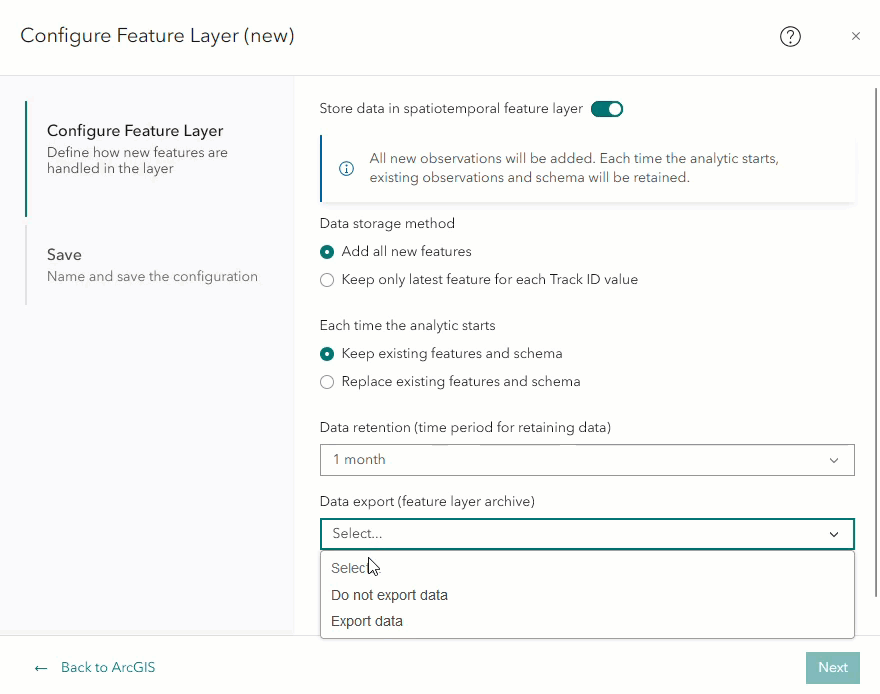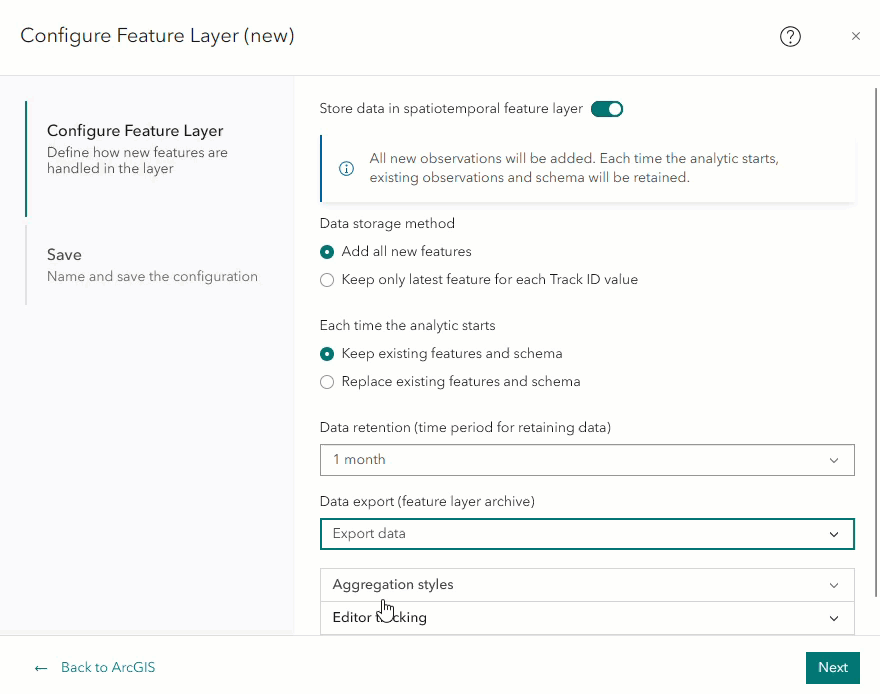
Real-time or big data analytics can write data to a feature layer output, which can be configured with data retention. To create a feature layer output, create or open an existing real-time or big data analytic. Then select Outputs > Feature Layer (new) on the left pane within the editor.
Note- You cannot configure data retention in existing feature layers. You will not be presented with data retention options if you add the output labeled Feature Layer (existing).
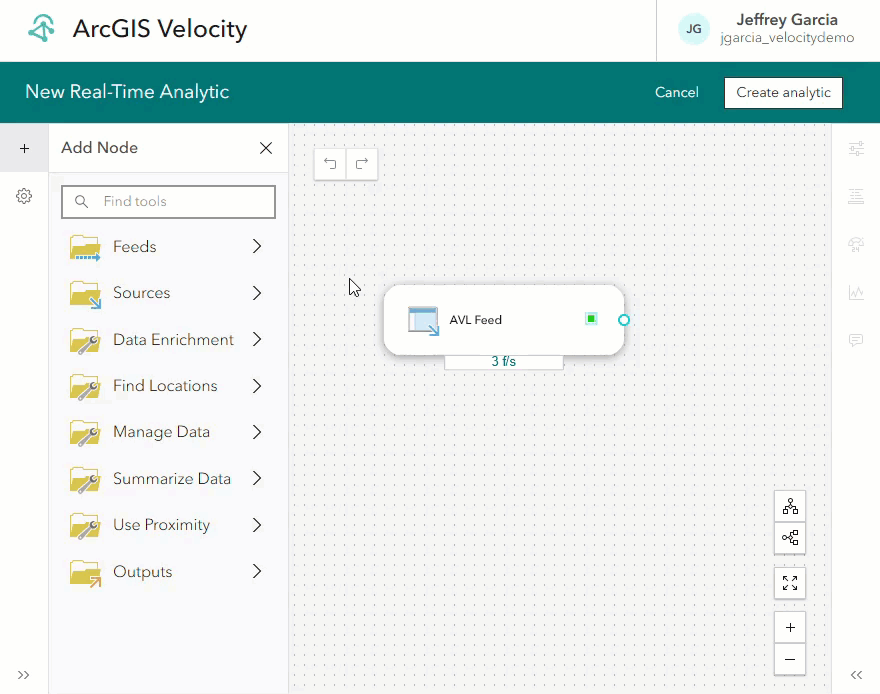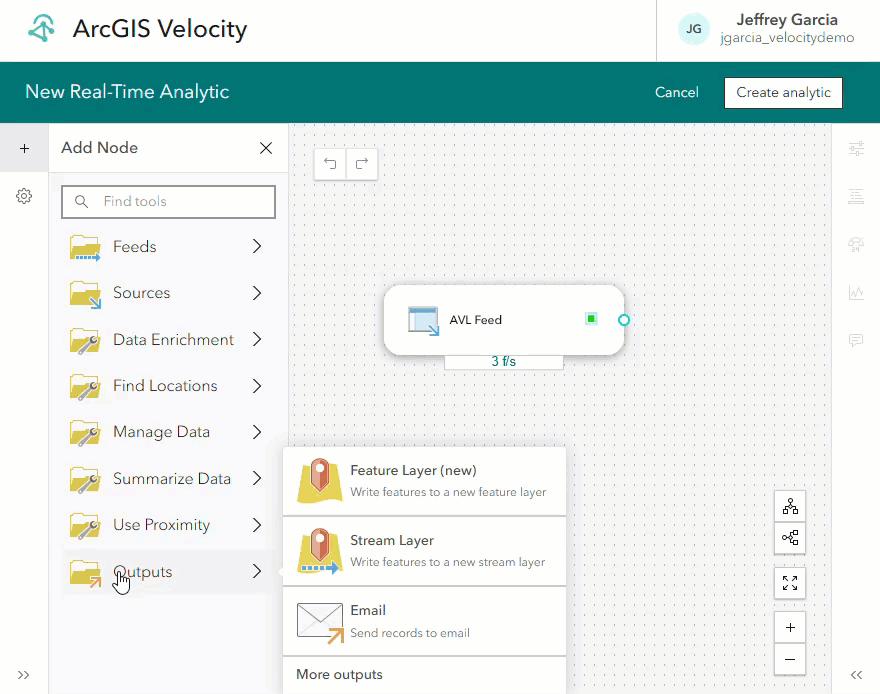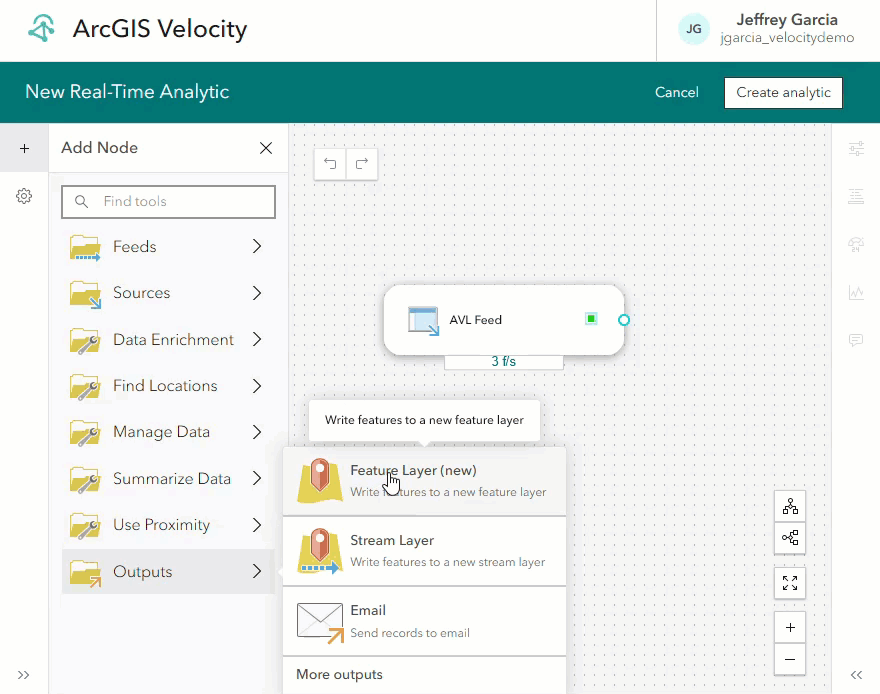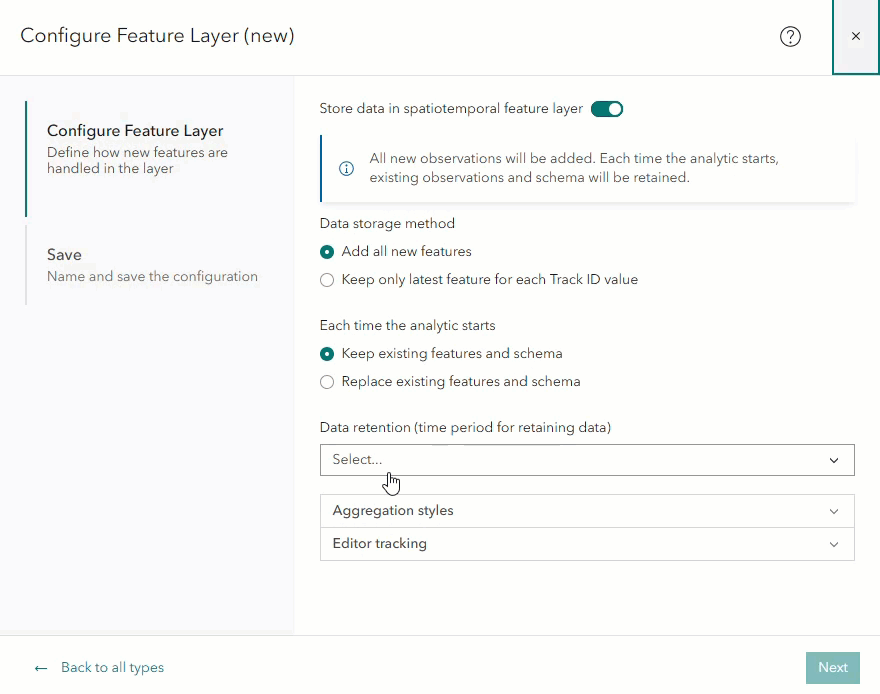

In the feature layer configuration window, there is a parameter labeled Data retention (time period for retaining data). This parameter is only visible if Store data in a spatiotemporal feature layer is enabled, and under Each time the analytic starts, Keep existing features and schema is selected. These parameters are selected by default. The data retention parameter is required when Keep existing features and schema is selected because once the analytic publishes the feature layer, it will and may indefinitely grow over time.
Note- If you disable Store data in a spatiotemporal feature layer, the analytic will create an ArcGIS Online hosted feature layer, which is incompatible with data retention. Therefore, disabling this will cause the data retention parameter to disappear.
Note- If you select Replace existing features and schema, the data retention parameter will disappear. This is because every time the analytic is started/restarted, any data previously stored in the layer will be discarded and overwritten by new features since starting the analytic.
The dropdown menu for data retention will display the following options:
- 1 hour
- 1 day
- 1 week
- 1 month
- 6 months
- 1 year
The amount of time you want to retain the data is up to you and may depend on your use case and organization’s available storage. We will explore this topic in the section: How long should I keep data in a feature layer?

After selecting the data retention option, another parameter labeled Data export (feature layer archive) will appear. Selecting the dropdown menu will display Do not export data and Export data. Selecting the Export data will enable Velocity to automatically export data older than the specified data retention period to a feature layer archive. Selecting Do not export data means that Velocity will automatically purge data older than the specified retention period. We will go into detail about how to ingest data from a feature layer archive in the later blog section: How do I ingest data from the feature layer archive?

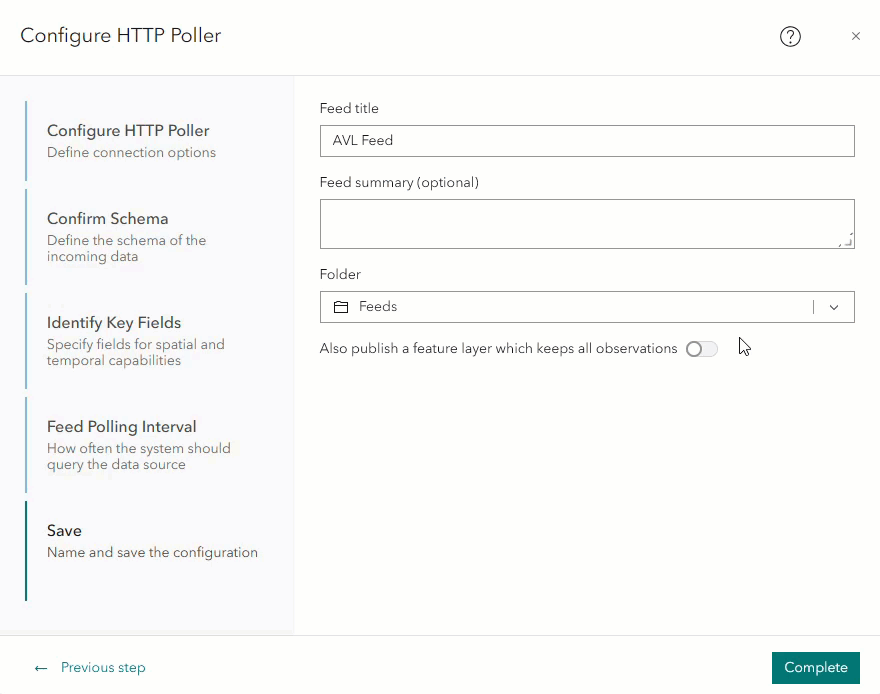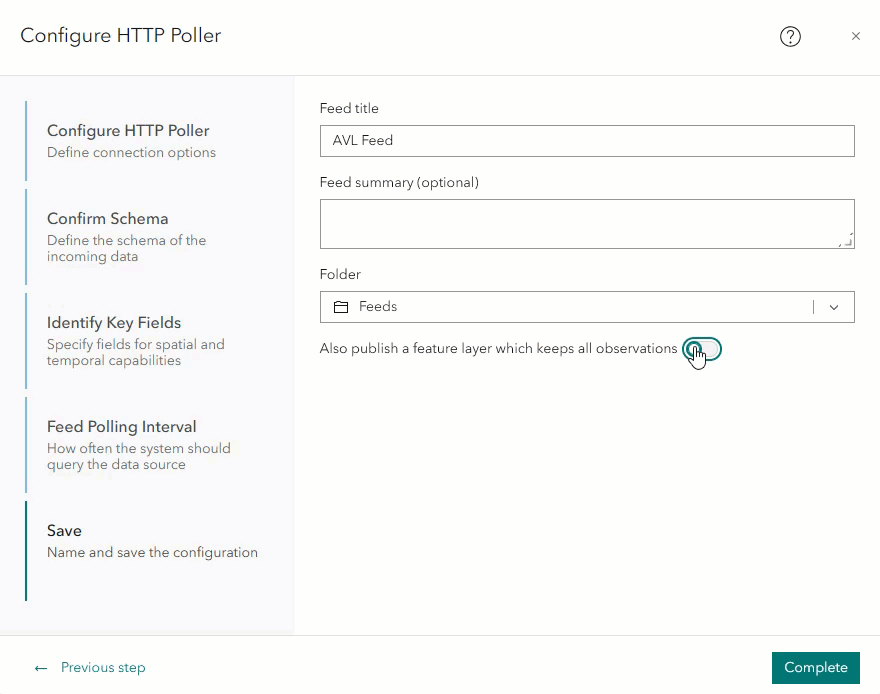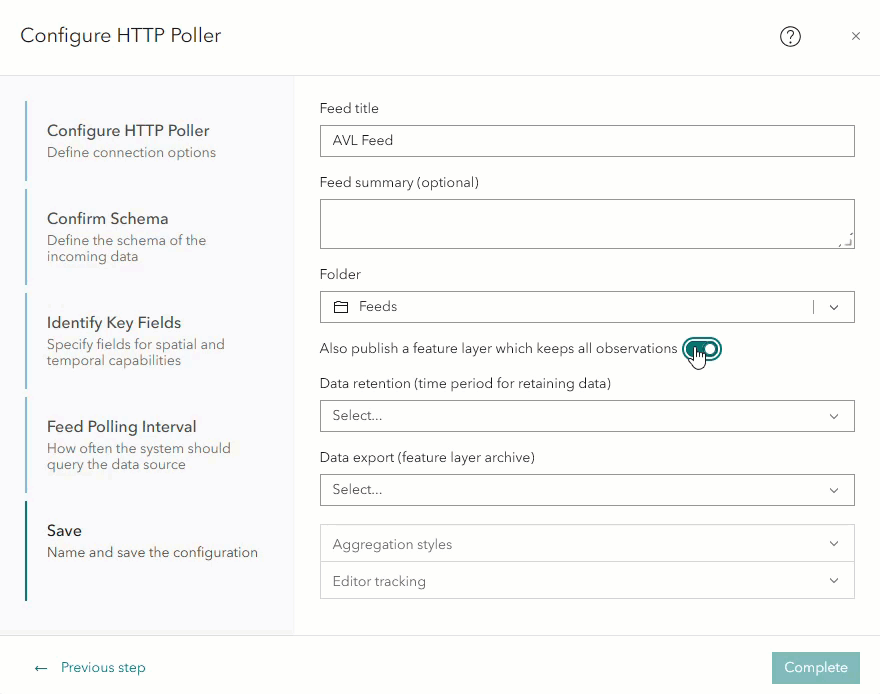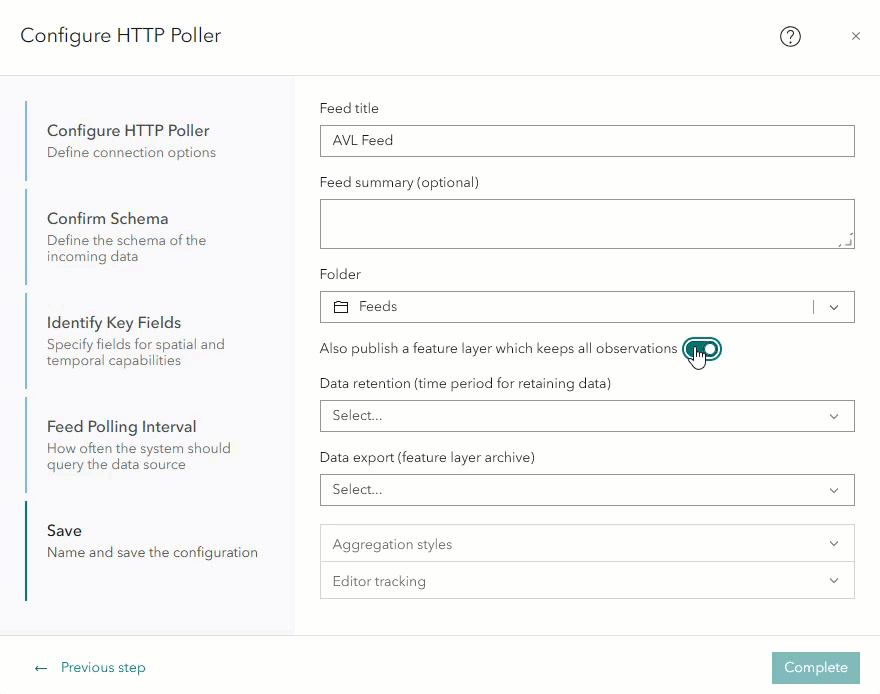
You can also configure data retention when creating a feed that will be published with a history feature layer. In the Save step during feed configuration, there is a parameter labeled Also publish a feature layer which keeps all observations. Enabling this parameter will allow Velocity to publish a feature layer that will store every record received by the feed. Once enabled, the data retention parameter will appear. You will also have the option to export the data after selecting a retention time period.
How long should I keep data in a feature layer?
You can a data retention period of 1 hour, 1 day, 1 week, 1 month, 6 months, and 1 year. When choosing how long to retain data, you should think about how long the data will remain relevant for your use case, and how much storage you’re willing to allocate to the feature layer. Below, we will consider two scenarios for choosing a data retention period.
Scenario 1
Consider a fleet of 10 vehicles transmitting their real-time position every second. This data is being written to a feature layer, and the records get updated with their new position every minute. At any given time, the feature layer will only have 10 records (unless you add a new vehicle to the fleet). Since the data is constantly being updated, there’s no need to set a long retention period. Setting a retention period of 1 hour or 1 day would be appropriate in this situation.
Scenario 2
Consider the same fleet of 10 vehicles in scenario 1 writing to a feature layer, except each record is added instead of updating existing records. The resulting feature layer would contain the vehicle’s historical track, enabling you to see a vehicle’s status in the past. This would involve selecting Add all new features for the Data storage method when configuring a feature layer output. In this context, retaining a larger amount of historical data for analysis or incident investigation may be beneficial. Therefore, selecting a longer retention period, such as one month, 6 months, or one year would be suitable.
A longer retention period would result in a larger amount of stored data. Therefore, it’s crucial to consider how the feature layer’s size will grow over time. The chart below shows the size of the feature layer for each data retention option at a rate of 10 KB/s (10 records that are 1 KB each).
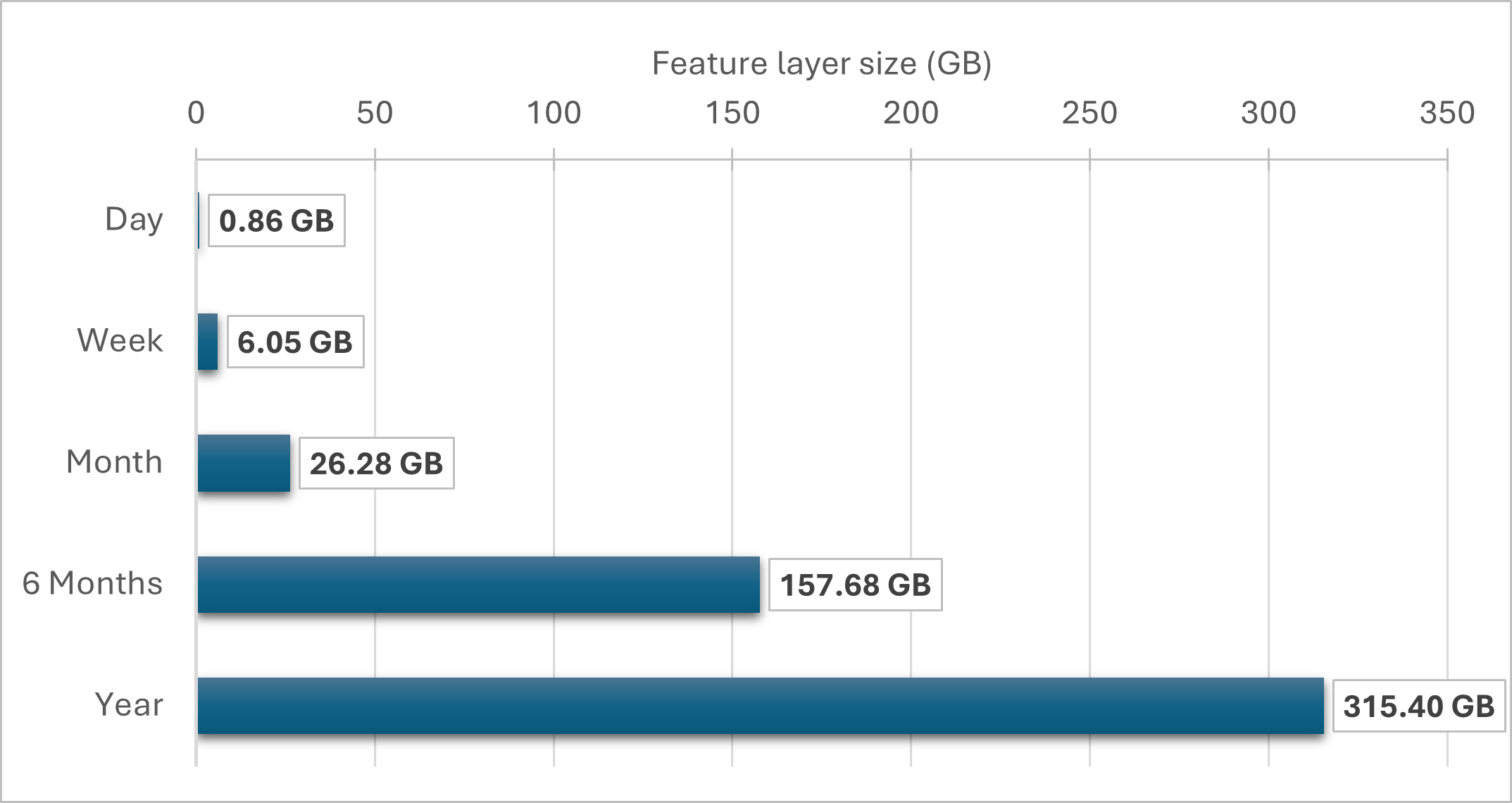
You should also consider the overall storage capacity of your subscription and how much storage you want to allocate to the feature layer. The amount of storage included in your subscription will depend on the license level. The table below shows the storage capacity for each license level.
| Standard | Advanced | Dedicated | |
| Storage capacity | 128 GB | 1 TB* | 3 TB and higher* |
In Velocity, you can check your Storage utilization by looking at the Storage in the Velocity homepage Subscription Utilization group.


Selecting the appropriate data retention period for your feature layer is crucial for optimizing both relevance and storage efficiency. By evaluating the nature of your data—whether it is real-time updates or historical records—you can make informed choices that align with your use case. As illustrated in the examples, a short retention period may be suitable for dynamic datasets, while longer retention is beneficial for historical analysis. Additionally, it is essential to monitor your storage capacity and utilization, especially in relation to your subscription level, to ensure that you are maximizing your resources effectively.
What is a feature layer archive?
When configuring a feature layer output and setting a data retention period, you are given the option to Export data. Choosing this option will mean that data older than the retention period will be removed from the feature layer and stored in a feature layer archive. Velocity will maintain the archived data for up to a year.
The feature layer will be created once the analytic is run. The data export process operates on a periodic schedule and will send data older than the set retention period to the feature layer archive. The feature layer archive is associated with the feature layer it was configured with and will not appear as a separate item in the Velocity and ArcGIS Online user-interface. To use the data exported to the feature layer archive, it must be added as a data source within a real-time or big data analytic. The steps for this will be covered in the next section.
Note- As the data export process operates on a periodic schedule, you may not immediately see records in the feature layer archive even though the retention time period has passed.
How do I use data stored in the feature layer archive?
To use the data that has been exported to the feature layer archive, the feature layer must be added as a data source in a real-time or big data analytic.
To get started, select Big Data under Analytics and select Create big data analytic. Select See all in the ArcGIS category > Feature Layer > Feature Layer (archive). From the list, choose the feature layer that was configured with data export.
Note- Only feature layers configured with data export will appear in the list. You will receive an error message if you select a feature layer with no archived data. Either not enough time has passed to exceed the data retention time period, or the periodic data export process has not yet occurred for this feature layer.
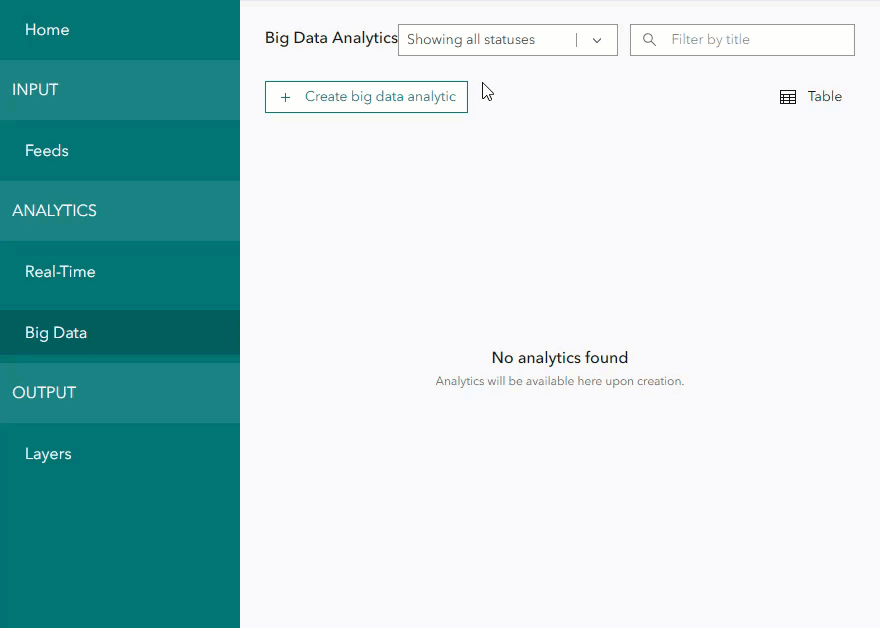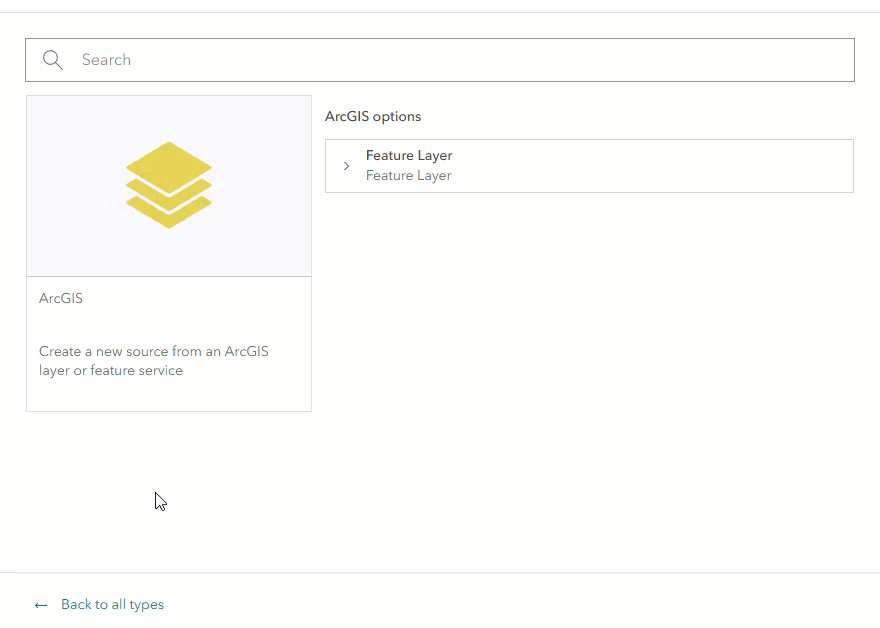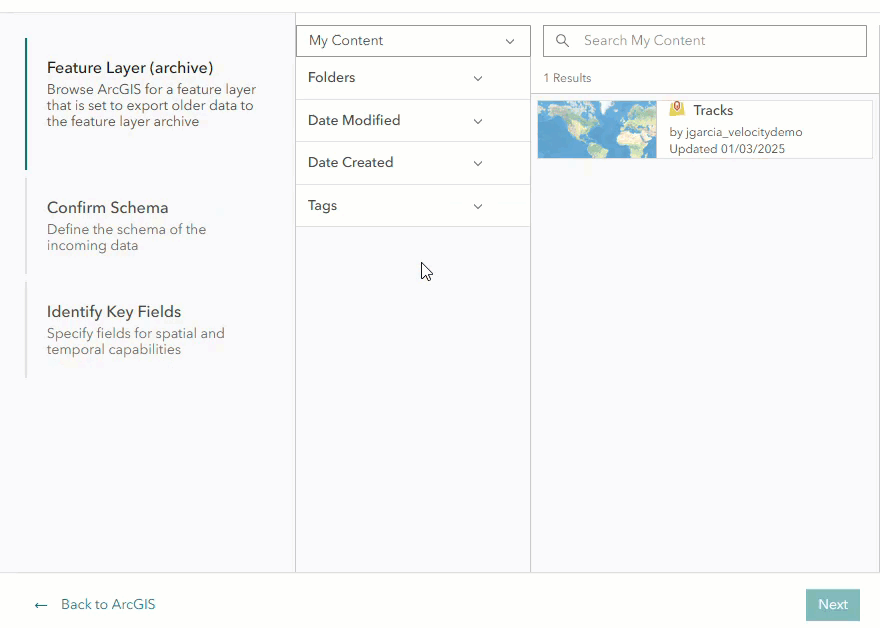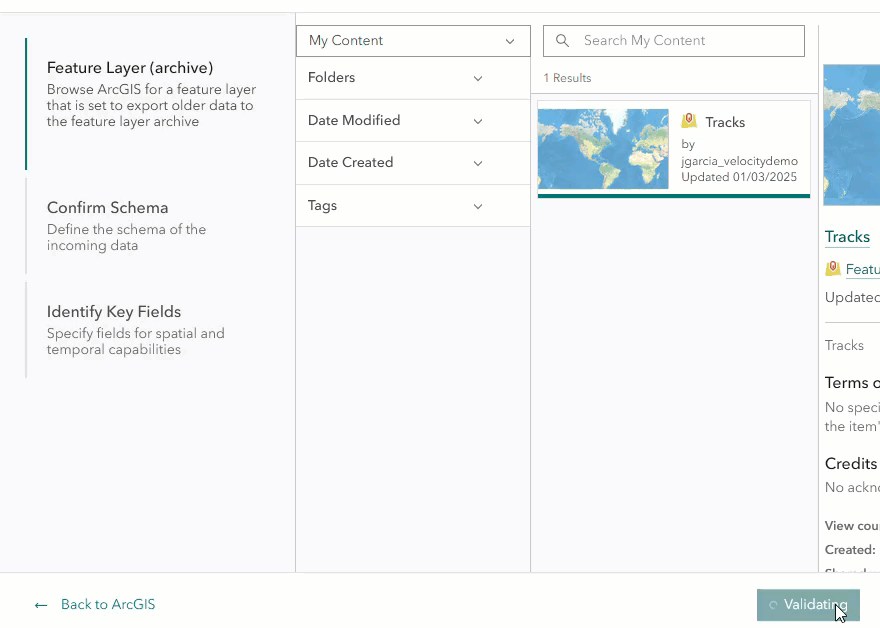
In the Confirm Schema section, the data will automatically be sampled and identified in Parquet format. Upon reviewing the schema, you may notice that four additional fields were added to the feature layer: objectid, globalid, SHAPE, and DATE. These are system-managed fields that are added when the feature layer is created. If you plan to send the data to an ArcGIS output, such as a feature layer or stream layer, uncheck or rename the SHAPE field. “SHAPE” is a reserved name and cannot be used.

In the Identify Key Fields section, the Location parameters will automatically be handled by the data source since the data is in Parquet format. Select a field for Start time if your data has a time field, then select a field to assign as the Track ID field. Click complete to create the data source.

With the feature layer archive configured as a data source, you can configure various tools to analyze patterns and trends and then send the data to various output types.
As stated earlier in the blog, Velocity maintains the archived data for up to a year. If you need to retain archived data indefinitely and have access to Amazon S3 or Azure Blob Storage, you can send the data to the associated output type in a big data analytic.

Merge a feature layer with its archive in a big data analytic
You can combine the datasets of a feature layer and its associated feature layer archive into a single pipeline for analysis. For example, let’s say our feature layer currently has data from the last week and our feature layer archive contains data from the previous12 months. These datasets can be combined using the Merge tool in a big data analytic.
To get started, select Big Data under Analytics and select Create big data analytic. Select See all in the ArcGIS category > Feature Layer > Feature Layer. Select the feature layer that was configured with data export and go through the rest of the configuration steps to add this data source. Once the feature layer with the current dataset has been added, go to the left pane and select Sources > More data sources > See all in the ArcGIS category > Feature Layer > Feature Layer (archive). In the list, select the same feature layer from the previous step.
Note- The feature layer and feature layer archive node labels will share the same name, and whichever item is added last will have “-1” appended to its label. For example, if you add the feature layer “Tracks” into the analytic, and then add its associated feature layer archive, the feature layer archive’s node label will be displayed as “Tracks-1”. You can leave it as is or rename the label to something like “Tracks (archive)”. This will help with keeping track of which data source node you’re working with.
After completing the steps, we have two feature layer data source nodes: one containing the current dataset and the other with the archived dataset. We will use the Merge tool to combine the two nodes. To add the tool, go to the left pane and select Manage Data > Merge. Connect the two data source nodes to the Merge tool node. Both datasets will merge into a single pipeline, which can be analyzed using additional tools and then sent to an output.

You may receive a validation error on the Merge tool, especially if you chose to keep all the fields when configuring both data sources.

As stated previously in the blog, objectid is one of the system-managed fields that were added when the feature layer was created. For the feature layer, the “OBJECT_ID” tag is automatically assigned to the objectid field automatically, but the tag does not get assigned to the feature layer archive’s objectid field. The feature layer and feature layer archive fields’ tags must match for a merge to be possible. You can resolve this by removing the objectid field in the Confirm Schema tab when configuring the data source.

Join a feature layer archive to a feed in a real-time analytic
The two previous scenarios involved ingesting a feature layer archive in a big data analytic. Real-time analytics are used to process and analyze real-time data coming from a feed. The feature layer archive is considered a static data source and cannot be added to real-time analytics by itself. For this reason, a join needs to be configured between the feed and feature layer archive. Using the Join Features tool, you can configure a spatial, temporal, or attribute-based join.
To get started, select Real-Time under Analytics and select Create real-time analytic. You can select an existing feed or configure a new feed to which you wish to join the feature layer archive data to. Once the feed has been configured and added to the real-time analytic, go to the left pane and select Sources > More data sources > See all in the ArcGIS category > Feature Layer > Feature Layer (archive). Now that the feed and feature layer archive data source have been added, we can configure the Join Features tool. In the left pane, select Summarize Data > Join Features. You can determine the join operation, relationship, and the rest of the options based on your use case with the data. Once the Join Features tool has been configured, you can add additional tools and then send the data to an output.

Conclusion
Data retention is a valuable solution for organizations that want to maintain feature layers at a manageable size in ArcGIS Velocity. When a data retention period is set for a feature layer, any features older than the specified duration are removed from the underlying dataset. This approach allows organizations to streamline their data storage by keeping only relevant data, thereby reducing storage space requirements. Organizations can still access historical data by exporting older records to a feature layer archive, which can be retrieved when analyzing historical information is needed.
We are always looking to hear back from the community, if you have any additional questions, please reach out to our team on the ArcGIS Velocity Community.
For more information, here are some helpful links:


Article Discussion: